イヤホンやヘッドホンの進化を語るとき、これまで主役だったのは「ノイズキャンセリング」でした。周囲の騒音を打ち消し、自分だけが静かな空間に入れるあの体験は、すでに多くの人にとって当たり前のものになっています。しかし、音の問題はそれだけではありません。とくにオープンイヤー型や耳を完全に塞がないウェアラブル機器では、「自分に聞こえるだけでなく、周囲にも聞こえてしまう」という別の課題が残ります。
今回取り上げるAppleの公開特許 US20260082146A1 は、まさにその問題に真正面から取り組んだ発明です。この特許の特徴は、従来のように外の騒音を消すのではなく、再生している音そのものの広がり方を制御し、ユーザー以外には聞こえにくくするという発想です。言い換えれば、これはノイズを制御するキャンセリングではなく、「音のプライバシー制御」を行うキャンセリング技術です。しかも、その実現手段は非常に興味深く、2つのスピーカードライバを使った空間的な音場設計と、状況に応じた信号処理の組み合わせにあります。
この記事では、Appleの特許出願 US20260082146A1 の発明の革新性と今後の応用可能性について解説します。
(この記事にない図面は、US20260082146A1 からご参照ください。)
発明の概要
デュアルスピーカー
この特許の中心にあるのは、1つのケースの中に配置された 第1スピーカードライバ(12)と 第2スピーカードライバ(13)です。両者は異なる位置に配置されていますが、共通バックボリューム(14)を共有します。この構成を持つ出力デバイス(3)は、ユーザーの耳の近くで音を出しつつ、必要に応じて パブリックモード と プライベートモード を切り替える仕組みとして説明されています。
パブリックモード
パブリックモードでは、2つのドライバを基本的に同相で駆動し、比較的自然に音を広げます。
プライベートモード
これに対してプライベートモードでは、2つのドライバの信号を非同相、つまり位相差を持つように制御し、特定の場所では音が強まり、別の場所では打ち消し合うような状態を作ります。これによって、ユーザーの耳には必要な音を届けながら、少し離れた第三者には聞こえにくい音場を形成します。
さらに、周囲に人がいるか、環境騒音がどの帯域でどれだけ強いか、といった条件を見ながら、周波数帯ごとにパブリックモードとプライベートモードを切り替えています。これは単なるスピーカー配置の特許ではなく、ハードウェアとソフトウェアを一体で設計した音響システムの提案だと言えます。
発明のポイント
共通バックボリュームを共有するデュアルスピーカーの基本構成
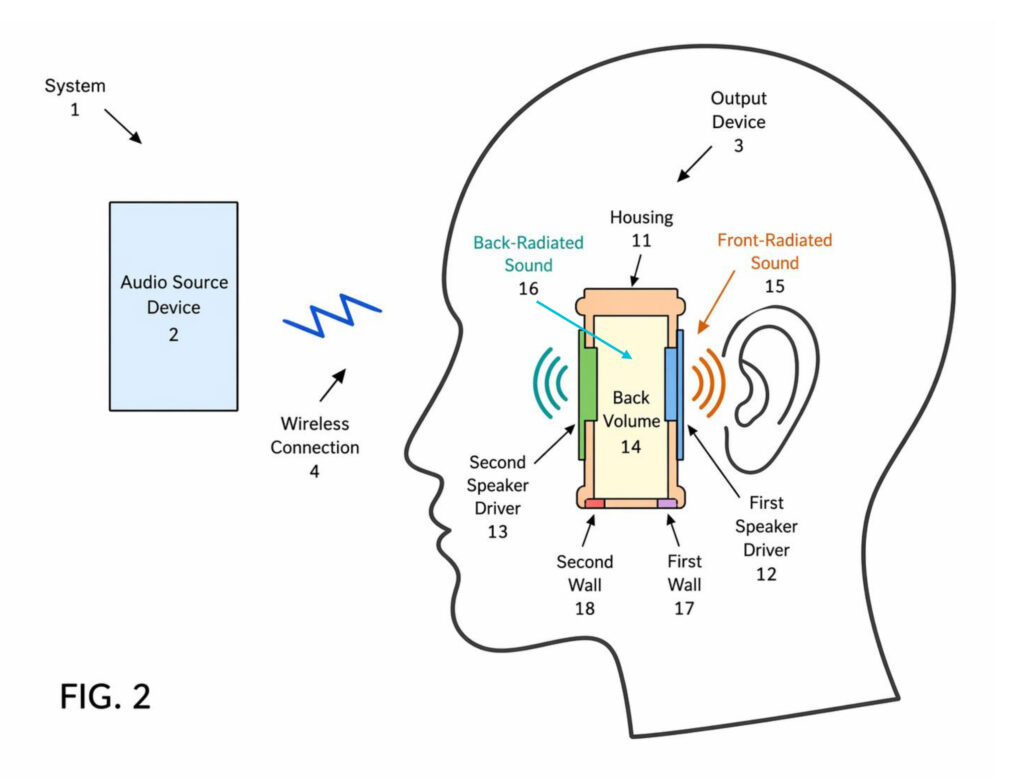
Fig.2は、この発明のデュアルスピーカーシステムの説明図です。
出力デバイス(3)の内部には ハウジング(11)があり、その中に 第1スピーカードライバ(12)と 第2スピーカードライバ(13)が異なる位置に配置されています。
特徴的なのは、両ドライバがそれぞれ独立した箱に入っているのではなく、内部の 共通バックボリューム(14)を共有している点です。第1スピーカードライバ(12)はユーザーの耳に近い側に、第2スピーカードライバ(13)は反対側に近い位置にあり、両者は異なる方向に音を放射します。図中では、前方に出る音が前方放射音(15)、背面側に回り込む音が後方放射音(16)として示されています。
ここで重要なのは、この2つのドライバをただ並べただけではないということです。共通バックボリューム(14)を共有することで、筐体内の空気ばねの挙動や低域の出方、さらには2つのドライバの相互作用まで含めて、1つの音響システムとして設計されています。
従来のノイズキャンセリングが「外乱を消す」方向の技術だとすれば、この発明は「自分が出したい音をどこにどう届かせるか」を扱う技術です。その意味では、ANC(アクティブノイズキャンセリング)のようなノイズ低減技術ではなく、ビームフォーミングや指向性スピーカーに近い発想が含まれています。その上で特徴的なのは、巨大なスピーカーアレイではなく、耳元に置けるほど小型のデバイスでそれをやろうとしていることです。ここに、ウェアラブル時代らしい設計思想があります。
(正確な図面は、US20260082146A1 をご参照ください。)
「周囲の状況を見て音の出し方を変える」制御アーキテクチャ
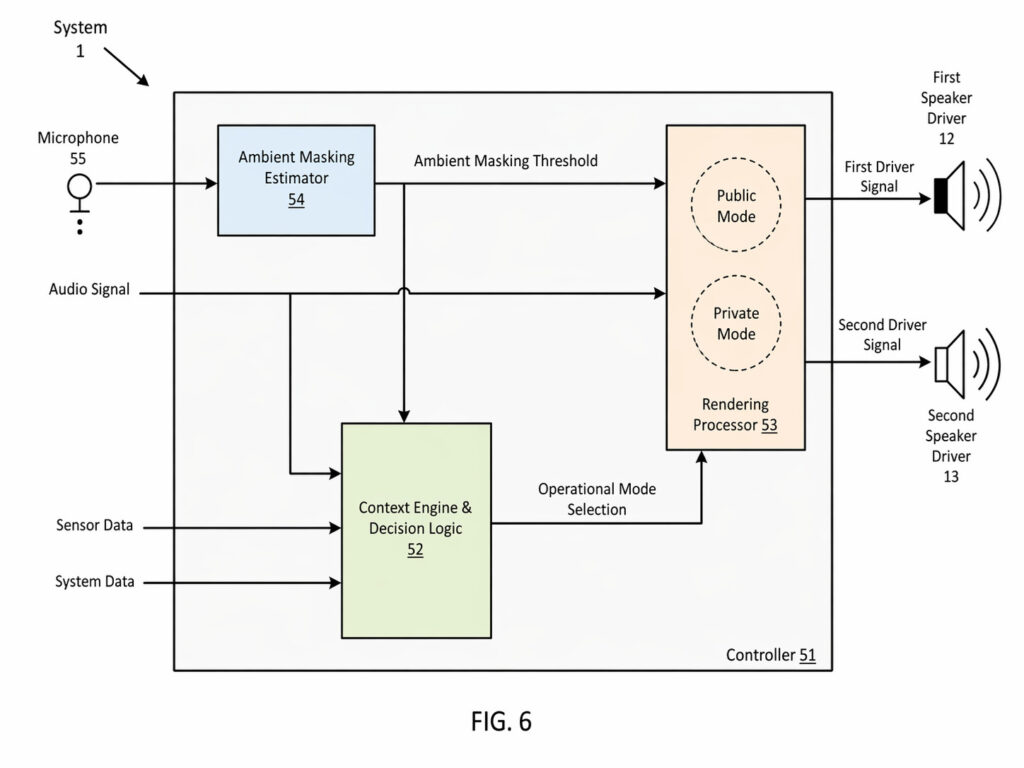
Fig.6は、音響制御のアーキテクチャを示したものです。コントローラ(51)は、コンテキストエンジン(52)、レンダリングプロセッサー(53)、アンビエントマスキング推定器(54)で構成されています。さらに、外部の環境音を拾うマイクロホン(55)と、実際に音を出す 第1スピーカードライバ(12)、第2スピーカードライバ(13 )が接続されています。
この構成のポイントは、まずアンビエントマスキング推定器(54)が環境騒音の周波数成分を見て、どの帯域が周囲の音に埋もれやすいかを推定することです。その情報を受けたコンテキストエンジン(52)は、たとえば近くに人がいるか、いま再生しているのが音楽か通話か、さらにバッテリー残量や内部温度がどうかといった条件まで考慮しながら、パブリックモードにするか、プライベートモードにするか、あるいは帯域ごとに両者を併用するかを決めます。最後にレンダリングプロセッサー(53)がその判断に基づいて、2つのスピーカードライバ用の信号を生成します。
このように、単に「逆相で信号を打ち消す」のではなく、周囲の状況を認識し、必要なときにだけプライバシー重視に切り替えるというユーザー重視の設計になっています。これは、オーディオ機器版のコンテキストアウェア・コンピューティングと言えるでしょう。将来的には、ユーザーが図書館にいるのか、駅にいるのか、家にいるのか、通話中なのか動画視聴中なのかに応じて、自動で最適な音響モードが選ばれるようになるかもしれません。特許本文にある通り、カメラや近接センサー、ユーザー設定、周囲雑音など複数の条件を合わせて判断できる設計になっているため、応用の幅はかなり広いです。
(正確な図面は、US20260082146A1 をご参照ください。)
ユーザーには音声、第三者にはマスキングノイズを向ける発想
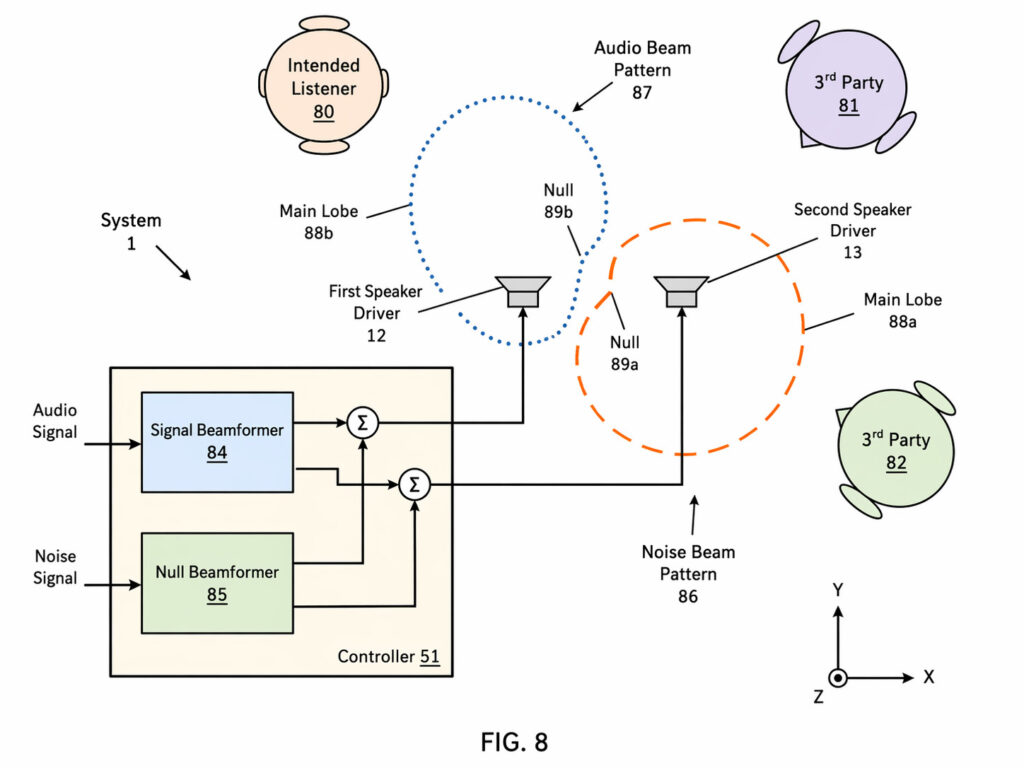
Fig.8は、音声をマスキングするノイズビームパターンを生成するシステムです。システム(1)は、ノイズビームパターン(86)とオーディオビームパターン(87)の2種類のビームを生成しています。
目的のリスナー(80)、つまり本来その音を聞くべきユーザーに対しては、メインローブ88b を持つオーディオビームパターン(87)が向けられます。一方で、周囲の第三者(81, 82)に対しては、メインローブ88a を持つノイズビームパターン(86)が向けられ、第三者方向にはオーディオビームが届かなくなります。
つまり、「聞かせたくない相手に対して、音を減らす」のではなく、「マスキングノイズを積極的に向けて、音を打ち消す」のです。言い換えれば、単に音漏れを小さくするだけでなく、空間の場所ごとにS/N比を作り分けて、ユーザーがいる領域では音声が優勢になり、第三者がいる領域ではノイズが優勢になるように制御します。
(正確な図面は、US20260082146A1 をご参照ください。)
他の図面の説明
(図面は、US20260082146A1 をご参照ください。)
Fig.1: 課題のイメージ
オープンイヤー型ヘッドホンなどでは会話の内容が外部に漏れてしまうという課題を説明する図です。
Fig.3:排気ポートがある出力装置
Fig.3は、Fig.2の構成に、出力装置から延びる細長い管(21)と排気ポート(22)とを追加した構成です。共通バックボリューム(14)に接続された管によって内部空気を逃がし、密閉容積による空気ばねの硬さを和らげることで、低域効率の改善を狙っています。
Fig.4:リアチャンバーのある出力装置
Fig.3は、Fig.2の構成に、リアチャンバー(41)とリアポート(42)を備えた構成です。第2スピーカードライバ(13)の周囲に開放型のリアチャンバーを設け、リアポート経由で音を放射することで、多重の音響効果を作り出します。プライベートモードのときの低域効率や歪みの改善にもつながる設計として説明されています。
Fig.5:排気ポートとリアチャンバーの両方がある出力装置
Fig.5は、Fig.3の排気ポート構成とFig.4のリアチャンバー構成を合わせた構成です。排気ポートとリアチャンバーを同時に持つことで、内部圧の緩和と放射特性の最適化を同時に狙う形態になっています。
Fig.7:システムのフローチャート
2つの動作モードのうちどちらで動作するかを決定する制御処理のフローチャートです。ブロック61 で音声信号を受け取り、ブロック62 で現在の動作モードを判定し、ブロック63 で第1・第2ドライバ用の信号を生成し、ブロック64 で実際に駆動します。
Fig.9:ゾーン毎の音声コンテンツの信号強度とノイズのグラフ
Fig.9は、音声とノイズの信号強度の関係を角度方向で示したグラフです。マスキングゾーン(91)、遷移ゾーン(92)、ターゲットゾーン(93) が描かれ、どの領域で第三者に聞こえにくくし、どの領域でユーザーに明瞭に聞かせるかが視覚化されています。
Fig.10:目的の聴取者の耳にヌル点を作る放射ビームパターン
Fig.10は、目的のユーザーの耳元でノイズが打ち消された状態を作る放射ビームパターン(101)の例です。第1スピーカードライバ(12)と第2スピーカードライバ(13)の出力差を利用して、ユーザーの耳ではノイズを抑えつつ、周囲にはノイズを広げることでマスキングを成立させます。
Fig.11:目的とする聴取者の耳に音を向ける放射ビームパターン
Fig.11は、目的のユーザーに放射ビームパターン(102)を向ける別の例です。こちらはユーザーが聞くべき音声を最大化するイメージで、Fig.10のノイズ制御と組み合わせれば、「自分には音声を、周囲にはノイズを」という放射ビームパターンが生成されます。
応用可能性
- この発明の応用先は、やはり耳を塞がないタイプのウェアラブルです。オープンイヤー型イヤホンやスマートグラスは、周囲の音を聞ける安心感がある一方で、通話や動画視聴の音漏れが避けにくいという弱点があります。この技術によって、開放感を保ちながら、周囲への漏れを抑えられる可能性があります。
- さらに、ノートPCやタブレット、車載シート、会議用卓上端末にも応用できそうです。たとえば一人だけにナビ音声を明瞭に届けたり、公共空間での個人通話を周囲に漏らしにくくしたりする用途は十分考えられます。将来的には、視線追跡や人物認識と組み合わせて、「誰に聞かせるか」をさらに精密に制御する方向へ進むかもしれません。
まとめ
- Appleの公開特許 US20260082146A1 は、外の騒音を消すことではなく、再生音の届き方そのものを制御する発明です。
- 2つのスピーカードライバと知能的な制御によって、ユーザーには聞こえ、周囲には聞こえにくい音場を作ろうとしている点が新しいです。
- オープンイヤー時代の開発の方向は、装着感ではなく、音のプライバシー設計になるのかもしれません。
最後までお読みいただきありがとうございました。
特許情報
特許番号:US 2026/0082146 A1
タイトル:Dual-Speaker System
発明者:Daniel K. Boothe, Martin E. Johnson, David Sumberg, David A. Kalinowski, Peter V. Jupin
出願人:Apple Inc.
出願日:2025/8/18
公開日:2026/3/19
特許の詳細については US20260082146A1 を参照してください。
※企業の特許は、製品になるものも、ならないものも、どちらも出願されます。今回紹介した特許が製品になるかどうか現時点では不明です。ご注意ください。